http://www.sisvel.com/images/2016/20160511-LTE-Sisvel_LTE_Patent_Pool_-_Brochure_v6.pdf
月度归档:2016年08月
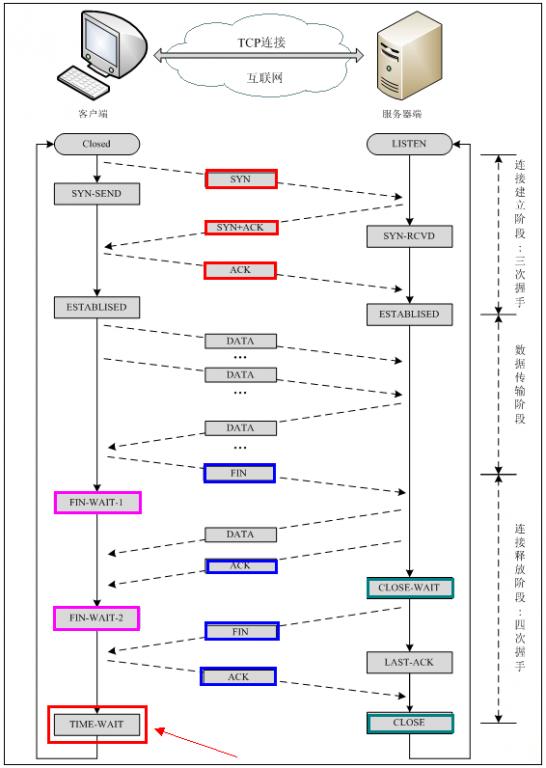
转:TCP协议中的三次握手和四次挥手
转:Linux上Core Dump文件的形成和分析
Core,又称之为Core Dump文件,是Unix/Linux操作系统的一种机制,对于线上服务而言,Core令人闻之色变,因为出Core的过程意味着服务暂时不能正常响应,需要恢复,并且随着吐Core进程的内存空间越大,此过程可能持续很长一段时间(例如当进程占用60G+以上内存时,完整Core文件需要15分钟才能完全写到磁盘上),这期间产生的流量损失,不可估量。
凡事皆有两面性,OS在出Core的同时,虽然会终止掉当前进程,但是也会保留下第一手的现场数据,OS仿佛是一架被按下快门的相机,而照片就是产出的Core文件。里面含有当进程被终止时内存、CPU寄存器等信息,可以供后续开发人员进行调试。
关于Core产生的原因很多,比如过去一些Unix的版本不支持现代Linux上这种GDB直接附着到进程上进行调试的机制,需要先向进程发送终止信号,然后用工具阅读core文件。在Linux上,我们就可以使用kill向一个指定的进程发送信号或者使用gcore命令来使其主动出Core并退出。如果从浅层次的原因上来讲,出Core意味着当前进程存在BUG,需要程序员修复。从深层次的原因上讲,是当前进程触犯了某些OS层级的保护机制,逼迫OS向当前进程发送诸如SIGSEGV(即signal 11)之类的信号, 例如访问空指针或数组越界出Core,实际上是触犯了OS的内存管理,访问了非当前进程的内存空间,OS需要通过出Core来进行警示,这就好像一个人身体内存在病毒,免疫系统就会通过发热来警示,并导致人体发烧是一个道理(有意思的是,并不是每次数组越界都会出Core,这和OS的内存管理中虚拟页面分配大小和边界有关,即使不出Core,也很有可能读到脏数据,引起后续程序行为紊乱,这是一种很难追查的BUG)。
说了这些,似乎感觉Core很强势,让人感觉缺乏控制力,其实不然。控制Core产生的行为和方式,有两个途径:
1.修改/proc/sys/kernel/core_pattern文件,此文件用于控制Core文件产生的文件名,默认情况下,此文件内容只有一行内容:“core”,此文件支持定制,一般使用%配合不同的字符,这里罗列几种:
%p 出Core进程的PID
%u 出Core进程的UID
%s 造成Core的signal号
%t 出Core的时间,从1970-01-0100:00:00开始的秒数
%e 出Core进程对应的可执行文件名
2.Ulimit –C命令,此命令可以显示当前OS对于Core文件大小的限制,如果为0,则表示不允许产生Core文件。如果想进行修改,可以使用:
Ulimit –cn
其中n为数字,表示允许Core文件体积的最大值,单位为Kb,如果想设为无限大,可以执行:
Ulimit -cunlimited
产生了Core文件之后,就是如何查看Core文件,并确定问题所在,进行修复。为此,我们不妨先来看看Core文件的格式,多了解一些Core文件。
首先可以明确一点,Core文件的格式ELF格式,这一点可以通过使用readelf -h命令来证实,如下图:
从读出来的ELF头信息可以看到,此文件类型为Core文件,那么readelf是如何得知的呢?可以从下面的数据结构中窥得一二:
其中当值为4的时候,表示当前文件为Core文件。如此,整个过程就很清楚了。
了解了这些之后,我们来看看如何阅读Core文件,并从中追查BUG。在Linux下,一般读取Core的命令为:
gdb exec_file core_file
使用GDB,先从可执行文件中读取符号表信息,然后读取Core文件。如果不与可执行文件搅合在一起可以吗?答案是不行,因为Core文件中没有符号表信息,无法进行调试,可以使用如下命令来验证:
Objdump –x core_file | tail
我们看到如下两行信息:
SYMBOL TABLE:
no symbols
表明当前的ELF格式文件中没有符号表信息。
为了解释如何看Core中信息,我们来举一个简单的例子:
#include “stdio.h”
int main(){
int stack_of[100000000];
int b=1;
int* a;
*a=b;
}
这段程序使用gcc –g a.c –o a进行编译,运行后直接会Core掉,使用gdb a core_file查看栈信息,可见其Core在了这行代码:
int stack_of[100000000];
原因很明显,直接在栈上申请如此大的数组,导致栈空间溢出,触犯了OS对于栈空间大小的限制,所以出Core(这里是否出Core还和OS对栈空间的大小配置有关,一般为8M)。但是这里要明确一点,真正出Core的代码不是分配栈空间的int stack_of[100000000], 而是后面这句int b=1, 为何?出Core的一种原因是因为对内存的非法访问,在上面的代码中分配数组stack_of时并未访问它,但是在其后声明变量并赋值,就相当于进行了越界访问,继而出Core。为了解释得更详细些,让我们使用gdb来看一下出Core的地方,使用命令gdb a core_file可见:
可知程序出现了段错误“Segmentation fault”, 代码是int b=1这句。我们来查看一下当前的栈信息:
其中可见指令指针rip指向地址为0×400473, 我们来看下当前的指令是什么:
这条movl指令要把立即数1送到0xffffffffe8287bfc(%rbp)这个地址去,其中rbp存储的是帧指针,而0xffffffffe8287bfc很明显是一个负数,结果计算为-400000004。这就可以解释了:其中我们申请的int stack_of[100000000]占用400000000字节,b是int类型,占用4个字节,且栈空间是由高地址向低地址延伸,那么b的栈地址就是0xffffffffe8287bfc(%rbp),也就是$rbp-400000004。当我们尝试访问此地址时:
可以看到无法访问此内存地址,这是因为它已经超过了OS允许的范围。
下面我们把程序进行改进:
#include “stdio.h”
int main(){
int* stack_of = malloc(sizeof(int)*100000000);
int b=1;
int* a;
*a=b;
}
使用gcc –O3 –g a.c –o a进行编译,运行后会再次Core掉,使用gdb查看栈信息,请见下图:
可见BUG出在第7行,也就是*a=b这句,这时我们尝试打印b的值,却发现符号表中找不到b的信息。为何?原因在于gcc使用了-O3参数,此参数可以对程序进行优化,一个负面效应是优化过程中会舍弃部分局部变量,导致调试时出现困难。在我们的代码中,b声明时即赋值,随后用于为*a赋值。优化后,此变量不再需要,直接为*a赋值为1即可,如果汇编级代码上讲,此优化可以减少一条MOV语句,节省一个寄存器。
此时我们的调试信息已经出现了一些扭曲,为此我们重新编译源程序,去掉-O3参数(这就解释了为何一些大型软件都会有debug版本存在,因为debug是未经优化的版本,包含了完整的符号表信息,易于调试),并重新运行,得到新的core并查看,如下图:
这次就比较明显了,b中的值没有问题,有问题的是a,其指向的地址是非法区域,也就是a没有分配内存导致的Core。当然,本例中的问题其实非常明显,几乎一眼就能看出来,但不妨碍它成为一个例子,用来解释在看Core过程中,需要注意的一些问题。
转: 十家你必須認識的NPE
蔣士棋╱北美智權報 編輯部
在產業界內,沒有人喜歡到處提告的「專利蟑螂」,因為它們往往都是憑著手中幾件專利就隨意向大公司討賠償,光是繁複的法律程序就搞得企業內的法務和專利人員苦不堪言。如果放寬一點來看,其實包括個人發明者、大學以及政府或民間資助的法人研究機構,都可以被納入所謂的NPE(Non-practicing Entities,非專利實施實體)當中,也有像ARM之類專門以技術授權金為營收來源的業者。不管喜不喜歡,第一步都得先從認識他們開始。
猜猜看:一件專利可以提起多少件侵權訴訟?想要回答這個問題,必須得認識US 6,266,674 B1這件專利。這件2001年獲證、所有權人為eDekka LLC的專利,目前總共提起了超過兩百件的專利侵權訴訟,盯上了256個被告。如果這件專利未來繼續有效,這兩個數字必然還會再攀升。
2015年,NPE控告人數與提告案量雙雙成長
根據RPX的調查,NPE的活動,經過2014年的沉寂後,到了2015年又回到高峰。就案量來看,從2010年至2013年,美國每年的專利侵權訴訟案都維持在700~800案的成長,其中由NPE所發動的案件數量,一度出現每年翻倍成長的趨勢(圖1),但在2014年、也就是美國正式實施專利複審程序(Inter Partes Review, IPR)之後的兩年,整體的案量出現明顯下滑,卻在2015年又回到2013年左右的水準。
圖1:2010~2015年美國專利侵權案件量(按NPE/非NPE區分)
資料來源:2015 NPE Activity
若是從被告人數來看,NPE的活動力更為明顯。在2015年,NPE以及非NPE以專利侵權提告的人數總和,是五年以來第二多的,然而,其中屬於非NPE案件的被告為2485名,反而是五年來最少的。也就是說,在2015由NPE提告的人數(5349名),已經大幅超越了過去數年(圖2)。
圖2:2010~2015年美國專利侵權案件被告人數(按NPE/非NPE區分)
資料來源:2015 NPE Activity
美國專利侵權訴訟的變化,與專利複審程序的改革不無關係。本刊在前文(USPTO提交多方專利複審程序(IPR)修正建議)中曾經分析,美國發明法案(AIA)實施的多方複審程序,可以讓被控侵權的廠商向專利訴訟及上訴委員會(PTAB),以更透明、成本更低廉的方式提出專利無效的異議,無形中增加了NPE興訟的成本,所以在2014年才會出現專利侵權訴訟案量與被告人數減少的現象;但就2015年的數字來看,似乎NPE也已經逐漸熟悉這套規則,也發展出了新的應對之道。未來IPR程序是否還能發揮牽制NPE的效果?值得繼續關注。
另一方面,包括前文提及的eDekka LLC在內,RPX也依據提告人數,統計出2015年全美前十大的NPE(見表1):
表1:2015年美國前10大NPE(按提告人數排序)
Rank NPE Defendants
1 Leigh M. Rothschild 139
2 eDekka LLC 102
3 IPNav 96
4 Empire IP LLC 81
5 Wi-LAN Inc. 75
6 CryptoPeak Solutions, LLC 65
7 Shipping & Transit, LLC 65
8 Hawk Technology Systems LLC 59
9 Olivistar LLC 57
10 Acacia Research Corporation 56
資料來源:2015 NPE Activity
從這份名單中可以發現,雖然有不少NPE僅以技術授權或訴訟維持營運,但排名第一的,卻是不折不扣的個人發明家。根據Rothschild本人的說法,比起把實際投入生產,他對於專心從事發明工作更有興趣。為了打點他的專利授權事業,Rothschild更成立了十家公司來分門別類管理他所發明的上百件專利。
美國前十大NPE 不乏專業發明人與資深科學家
此外,排名第五的Wi-LAN Inc.可是大有來頭,創辦人之一的Hatim Zaghloul在通訊領域就是個大師級人物,其所發明的WODFM技術也是IEEE在802.11a的產業標準。2014年,Wi-LAN Inc.的權利金收入就高達9千8百萬美元(約32億台幣)。
在美國,專利產業的發展百花齊放,即使大多數的NPE仍然以興訟為主業,但不可否認的是,NPE也讓只懂技術鑽研卻無力付諸生產的純發明家們,多了個獲利的機會。就算再怎麼不認同他們的濫訴手法,也必須正視此一現象的存在,並及早規劃應對方法,若是真的被盯上,恐怕就後悔莫及了。
參考資料:
2015 NPE Activity, PRX Corporation, 2016/01/04
Leigh Rothschild | Intellectual Ventures, Inventor Spotlight, Intellectual Ventures,
WiLAN
转: USPTO提交多方專利複審程序(IPR)修正建議
蔣士棋╱北美智權報 編輯部
2011年開始實施的美國發明法案(Leahy-Smith America Invents Act),堪稱近年來美國專利制度的最大一次變革;在實施滿四年之後,今年九月,美國專利商標局(USPTO)向美國國會提交了一份關於美國發明法案(AIA)的檢討研究報告,其中最值得台灣廠商注意的,就是多方複審程序的兩大修正建議。
2011年,美國國會通過了由Leahy以及Smith兩位議員領銜的美國發明法案(AIA),引進了許多新制度,大幅改變既有的美國專利遊戲規則,例如專利所有權的認定基準,從長年施行的先發明原則(first-to-invent)改變為先申請原則(first-inventor-to-file)、允許USPTO自訂專利年費規則、允許第三人在專利審查階段案提出先前技術等等;但最重要的,恐怕還是專利獲證後的異議程序。
根據AIA的規定,一項專利獲證之後,如果第三人有異議,可以在獲證之後的九個月內提出領證後複審(Post Grant Review, PGR),若是超過九個月,則需提出多方複審(Inter Partes Review, IPR)。兩項複審程序;其中PGR可針對專利的新穎性、進步性和專利文件缺漏提出異議,但IPR則只能對新穎性、進步性等可專利性的實質要件提出異議。
實施AIA後,專利獲證後異議程序更加接近司法運作
這兩項複審程序都必須由新成立的專利訴訟及上訴委員會(Patent Trial and Appeal Board, PTAB)進行審理。與過去的覆核(Re-examination)不同的是,PTAB的運作更加接近司法系統:對於每一件異議案,PTAB都會由三名資深審查官轉任的專利裁判員(Administrative Patent Judges, APJ)進行裁判,如果遇到特別困難的案件,可增加APJ的人數至七名,與司法系統中的聯席審判制度(en banc)類似。如果異議雙方對於PTAB的裁決結果不符,可再向管轄智財權案件的美國聯邦巡迴上訴法院(CAFC)提請上訴。
Orrick Law Firm合夥律師張亞樵解釋,實施IPR的目的是為了改進過去覆核制度成本高昂、效率低落的缺點,進而使專利複審更透明而具彈性,例如只要異議人與專利權人達成和解(settlement),PGR與IPR的程序都可以隨時終止。自從2012年實施以來,PTAB每年的IPR收案量都相當顯著地成長,如2014年時聲請IPR的案件數共1310件,但2015年度光是上半年,IPR收件數就高達1319件(表1)。
表1:PTAB歷年IPR案件處理狀況統計
資料來源:http://uspto.gov
張亞樵指出,PTAB在累積了數千件的裁判經驗後,發現在IPR的審判程序上有兩點應該進行修正。首先,在實務上,美國許多非專利實施實體(Non-Practice Entity, NPE)會以同一件專利向不同廠商控告侵權,為了反制此類濫訴,遭控告的廠商都會向PTAB申請IPR;如此一來,就會有許多異議人對同樣一件專利申請多方複審,徒增行政上的困擾。PTAB建議的修正方向,就是參考美國民事裁判中的團體訴訟(class action)制度,讓在相近時間內、對於同一件專利提出IPR的異議人加入同一件裁判案,以減輕聲請人以及PTAB的負擔並加快IPR進程。
IPR的利害關係人揭露應給予補正機會
此外,在IPR程序中,聲請人必須在提出聲請時就列齊所有利害關係人(real parties in interest)。張亞樵指出,這一條規定對於「利害關係人」的定義太過於寬廣,以至於每年有許多IPR複審案,就是因為這項缺失而無法成案。他舉例,「如果一家公司把自己的專利分割出來成立一家新公司,這家新公司申請IPR時,母公司要不要列入利害關係人?或者當群創申請IPR時,鴻海算不算他的利害關係人?如果鴻海算,那鴻海旗下的子公司是不是也得全部列出來?」PTAB因此建議,因為利害關係人的認定在每個案例上都不盡相同,只要聲請人不是故意欺瞞,都應該允許其在事後一定期間內補充或修正,以免聲請人的權益因此受損。
不過,張亞樵還是提醒,雖然PTAB的運作相當接近司法審判,但與真正的民事訴訟還是有差距。「美國的民事程序允許中途加入新證據、加入新的原告或被告,但是IPR爭執的就是專利本身的專利性,」張亞樵解釋,在IPR中,獲勝的關鍵其實就是一開始提交給PTAB的書面資料,如果內容不夠充分,後續就很難扳回劣勢;而且,因為參與裁判的APJ都是資深的專利審查官,聲請人也應該有被問及專業技術問題的準備。總而言之,在提出IPR前就把事實以及技術相關資料準備妥當,不過度依賴訴訟技巧,就是在IPR中獲勝的關鍵。
資料來源:
「通訊產業專利趨勢與訴訟分析」研討會會議資料
Report to Congress – Study and Report on the Implementation of the Leahy-Smith America Invents Act, USPTO, Sep. 2015