转:Linux上Core Dump文件的形成和分析
Core,又称之为Core Dump文件,是Unix/Linux操作系统的一种机制,对于线上服务而言,Core令人闻之色变,因为出Core的过程意味着服务暂时不能正常响应,需要恢复,并且随着吐Core进程的内存空间越大,此过程可能持续很长一段时间(例如当进程占用60G+以上内存时,完整Core文件需要15分钟才能完全写到磁盘上),这期间产生的流量损失,不可估量。
凡事皆有两面性,OS在出Core的同时,虽然会终止掉当前进程,但是也会保留下第一手的现场数据,OS仿佛是一架被按下快门的相机,而照片就是产出的Core文件。里面含有当进程被终止时内存、CPU寄存器等信息,可以供后续开发人员进行调试。
关于Core产生的原因很多,比如过去一些Unix的版本不支持现代Linux上这种GDB直接附着到进程上进行调试的机制,需要先向进程发送终止信号,然后用工具阅读core文件。在Linux上,我们就可以使用kill向一个指定的进程发送信号或者使用gcore命令来使其主动出Core并退出。如果从浅层次的原因上来讲,出Core意味着当前进程存在BUG,需要程序员修复。从深层次的原因上讲,是当前进程触犯了某些OS层级的保护机制,逼迫OS向当前进程发送诸如SIGSEGV(即signal 11)之类的信号, 例如访问空指针或数组越界出Core,实际上是触犯了OS的内存管理,访问了非当前进程的内存空间,OS需要通过出Core来进行警示,这就好像一个人身体内存在病毒,免疫系统就会通过发热来警示,并导致人体发烧是一个道理(有意思的是,并不是每次数组越界都会出Core,这和OS的内存管理中虚拟页面分配大小和边界有关,即使不出Core,也很有可能读到脏数据,引起后续程序行为紊乱,这是一种很难追查的BUG)。
说了这些,似乎感觉Core很强势,让人感觉缺乏控制力,其实不然。控制Core产生的行为和方式,有两个途径:
1.修改/proc/sys/kernel/core_pattern文件,此文件用于控制Core文件产生的文件名,默认情况下,此文件内容只有一行内容:“core”,此文件支持定制,一般使用%配合不同的字符,这里罗列几种:
%p 出Core进程的PID
%u 出Core进程的UID
%s 造成Core的signal号
%t 出Core的时间,从1970-01-0100:00:00开始的秒数
%e 出Core进程对应的可执行文件名
2.Ulimit –C命令,此命令可以显示当前OS对于Core文件大小的限制,如果为0,则表示不允许产生Core文件。如果想进行修改,可以使用:
Ulimit –cn
其中n为数字,表示允许Core文件体积的最大值,单位为Kb,如果想设为无限大,可以执行:
Ulimit -cunlimited
产生了Core文件之后,就是如何查看Core文件,并确定问题所在,进行修复。为此,我们不妨先来看看Core文件的格式,多了解一些Core文件。
首先可以明确一点,Core文件的格式ELF格式,这一点可以通过使用readelf -h命令来证实,如下图:
从读出来的ELF头信息可以看到,此文件类型为Core文件,那么readelf是如何得知的呢?可以从下面的数据结构中窥得一二:
其中当值为4的时候,表示当前文件为Core文件。如此,整个过程就很清楚了。
了解了这些之后,我们来看看如何阅读Core文件,并从中追查BUG。在Linux下,一般读取Core的命令为:
gdb exec_file core_file
使用GDB,先从可执行文件中读取符号表信息,然后读取Core文件。如果不与可执行文件搅合在一起可以吗?答案是不行,因为Core文件中没有符号表信息,无法进行调试,可以使用如下命令来验证:
Objdump –x core_file | tail
我们看到如下两行信息:
SYMBOL TABLE:
no symbols
表明当前的ELF格式文件中没有符号表信息。
为了解释如何看Core中信息,我们来举一个简单的例子:
#include “stdio.h”
int main(){
int stack_of[100000000];
int b=1;
int* a;
*a=b;
}
这段程序使用gcc –g a.c –o a进行编译,运行后直接会Core掉,使用gdb a core_file查看栈信息,可见其Core在了这行代码:
int stack_of[100000000];
原因很明显,直接在栈上申请如此大的数组,导致栈空间溢出,触犯了OS对于栈空间大小的限制,所以出Core(这里是否出Core还和OS对栈空间的大小配置有关,一般为8M)。但是这里要明确一点,真正出Core的代码不是分配栈空间的int stack_of[100000000], 而是后面这句int b=1, 为何?出Core的一种原因是因为对内存的非法访问,在上面的代码中分配数组stack_of时并未访问它,但是在其后声明变量并赋值,就相当于进行了越界访问,继而出Core。为了解释得更详细些,让我们使用gdb来看一下出Core的地方,使用命令gdb a core_file可见:
可知程序出现了段错误“Segmentation fault”, 代码是int b=1这句。我们来查看一下当前的栈信息:
其中可见指令指针rip指向地址为0×400473, 我们来看下当前的指令是什么:
这条movl指令要把立即数1送到0xffffffffe8287bfc(%rbp)这个地址去,其中rbp存储的是帧指针,而0xffffffffe8287bfc很明显是一个负数,结果计算为-400000004。这就可以解释了:其中我们申请的int stack_of[100000000]占用400000000字节,b是int类型,占用4个字节,且栈空间是由高地址向低地址延伸,那么b的栈地址就是0xffffffffe8287bfc(%rbp),也就是$rbp-400000004。当我们尝试访问此地址时:
可以看到无法访问此内存地址,这是因为它已经超过了OS允许的范围。
下面我们把程序进行改进:
#include “stdio.h”
int main(){
int* stack_of = malloc(sizeof(int)*100000000);
int b=1;
int* a;
*a=b;
}
使用gcc –O3 –g a.c –o a进行编译,运行后会再次Core掉,使用gdb查看栈信息,请见下图:
可见BUG出在第7行,也就是*a=b这句,这时我们尝试打印b的值,却发现符号表中找不到b的信息。为何?原因在于gcc使用了-O3参数,此参数可以对程序进行优化,一个负面效应是优化过程中会舍弃部分局部变量,导致调试时出现困难。在我们的代码中,b声明时即赋值,随后用于为*a赋值。优化后,此变量不再需要,直接为*a赋值为1即可,如果汇编级代码上讲,此优化可以减少一条MOV语句,节省一个寄存器。
此时我们的调试信息已经出现了一些扭曲,为此我们重新编译源程序,去掉-O3参数(这就解释了为何一些大型软件都会有debug版本存在,因为debug是未经优化的版本,包含了完整的符号表信息,易于调试),并重新运行,得到新的core并查看,如下图:
这次就比较明显了,b中的值没有问题,有问题的是a,其指向的地址是非法区域,也就是a没有分配内存导致的Core。当然,本例中的问题其实非常明显,几乎一眼就能看出来,但不妨碍它成为一个例子,用来解释在看Core过程中,需要注意的一些问题。
转: 十家你必須認識的NPE
蔣士棋╱北美智權報 編輯部
在產業界內,沒有人喜歡到處提告的「專利蟑螂」,因為它們往往都是憑著手中幾件專利就隨意向大公司討賠償,光是繁複的法律程序就搞得企業內的法務和專利人員苦不堪言。如果放寬一點來看,其實包括個人發明者、大學以及政府或民間資助的法人研究機構,都可以被納入所謂的NPE(Non-practicing Entities,非專利實施實體)當中,也有像ARM之類專門以技術授權金為營收來源的業者。不管喜不喜歡,第一步都得先從認識他們開始。
猜猜看:一件專利可以提起多少件侵權訴訟?想要回答這個問題,必須得認識US 6,266,674 B1這件專利。這件2001年獲證、所有權人為eDekka LLC的專利,目前總共提起了超過兩百件的專利侵權訴訟,盯上了256個被告。如果這件專利未來繼續有效,這兩個數字必然還會再攀升。
2015年,NPE控告人數與提告案量雙雙成長
根據RPX的調查,NPE的活動,經過2014年的沉寂後,到了2015年又回到高峰。就案量來看,從2010年至2013年,美國每年的專利侵權訴訟案都維持在700~800案的成長,其中由NPE所發動的案件數量,一度出現每年翻倍成長的趨勢(圖1),但在2014年、也就是美國正式實施專利複審程序(Inter Partes Review, IPR)之後的兩年,整體的案量出現明顯下滑,卻在2015年又回到2013年左右的水準。
圖1:2010~2015年美國專利侵權案件量(按NPE/非NPE區分)
資料來源:2015 NPE Activity
若是從被告人數來看,NPE的活動力更為明顯。在2015年,NPE以及非NPE以專利侵權提告的人數總和,是五年以來第二多的,然而,其中屬於非NPE案件的被告為2485名,反而是五年來最少的。也就是說,在2015由NPE提告的人數(5349名),已經大幅超越了過去數年(圖2)。
圖2:2010~2015年美國專利侵權案件被告人數(按NPE/非NPE區分)
資料來源:2015 NPE Activity
美國專利侵權訴訟的變化,與專利複審程序的改革不無關係。本刊在前文(USPTO提交多方專利複審程序(IPR)修正建議)中曾經分析,美國發明法案(AIA)實施的多方複審程序,可以讓被控侵權的廠商向專利訴訟及上訴委員會(PTAB),以更透明、成本更低廉的方式提出專利無效的異議,無形中增加了NPE興訟的成本,所以在2014年才會出現專利侵權訴訟案量與被告人數減少的現象;但就2015年的數字來看,似乎NPE也已經逐漸熟悉這套規則,也發展出了新的應對之道。未來IPR程序是否還能發揮牽制NPE的效果?值得繼續關注。
另一方面,包括前文提及的eDekka LLC在內,RPX也依據提告人數,統計出2015年全美前十大的NPE(見表1):
表1:2015年美國前10大NPE(按提告人數排序)
Rank NPE Defendants
1 Leigh M. Rothschild 139
2 eDekka LLC 102
3 IPNav 96
4 Empire IP LLC 81
5 Wi-LAN Inc. 75
6 CryptoPeak Solutions, LLC 65
7 Shipping & Transit, LLC 65
8 Hawk Technology Systems LLC 59
9 Olivistar LLC 57
10 Acacia Research Corporation 56
資料來源:2015 NPE Activity
從這份名單中可以發現,雖然有不少NPE僅以技術授權或訴訟維持營運,但排名第一的,卻是不折不扣的個人發明家。根據Rothschild本人的說法,比起把實際投入生產,他對於專心從事發明工作更有興趣。為了打點他的專利授權事業,Rothschild更成立了十家公司來分門別類管理他所發明的上百件專利。
美國前十大NPE 不乏專業發明人與資深科學家
此外,排名第五的Wi-LAN Inc.可是大有來頭,創辦人之一的Hatim Zaghloul在通訊領域就是個大師級人物,其所發明的WODFM技術也是IEEE在802.11a的產業標準。2014年,Wi-LAN Inc.的權利金收入就高達9千8百萬美元(約32億台幣)。
在美國,專利產業的發展百花齊放,即使大多數的NPE仍然以興訟為主業,但不可否認的是,NPE也讓只懂技術鑽研卻無力付諸生產的純發明家們,多了個獲利的機會。就算再怎麼不認同他們的濫訴手法,也必須正視此一現象的存在,並及早規劃應對方法,若是真的被盯上,恐怕就後悔莫及了。
參考資料:
2015 NPE Activity, PRX Corporation, 2016/01/04
Leigh Rothschild | Intellectual Ventures, Inventor Spotlight, Intellectual Ventures,
WiLAN
转: USPTO提交多方專利複審程序(IPR)修正建議
蔣士棋╱北美智權報 編輯部
2011年開始實施的美國發明法案(Leahy-Smith America Invents Act),堪稱近年來美國專利制度的最大一次變革;在實施滿四年之後,今年九月,美國專利商標局(USPTO)向美國國會提交了一份關於美國發明法案(AIA)的檢討研究報告,其中最值得台灣廠商注意的,就是多方複審程序的兩大修正建議。
2011年,美國國會通過了由Leahy以及Smith兩位議員領銜的美國發明法案(AIA),引進了許多新制度,大幅改變既有的美國專利遊戲規則,例如專利所有權的認定基準,從長年施行的先發明原則(first-to-invent)改變為先申請原則(first-inventor-to-file)、允許USPTO自訂專利年費規則、允許第三人在專利審查階段案提出先前技術等等;但最重要的,恐怕還是專利獲證後的異議程序。
根據AIA的規定,一項專利獲證之後,如果第三人有異議,可以在獲證之後的九個月內提出領證後複審(Post Grant Review, PGR),若是超過九個月,則需提出多方複審(Inter Partes Review, IPR)。兩項複審程序;其中PGR可針對專利的新穎性、進步性和專利文件缺漏提出異議,但IPR則只能對新穎性、進步性等可專利性的實質要件提出異議。
實施AIA後,專利獲證後異議程序更加接近司法運作
這兩項複審程序都必須由新成立的專利訴訟及上訴委員會(Patent Trial and Appeal Board, PTAB)進行審理。與過去的覆核(Re-examination)不同的是,PTAB的運作更加接近司法系統:對於每一件異議案,PTAB都會由三名資深審查官轉任的專利裁判員(Administrative Patent Judges, APJ)進行裁判,如果遇到特別困難的案件,可增加APJ的人數至七名,與司法系統中的聯席審判制度(en banc)類似。如果異議雙方對於PTAB的裁決結果不符,可再向管轄智財權案件的美國聯邦巡迴上訴法院(CAFC)提請上訴。
Orrick Law Firm合夥律師張亞樵解釋,實施IPR的目的是為了改進過去覆核制度成本高昂、效率低落的缺點,進而使專利複審更透明而具彈性,例如只要異議人與專利權人達成和解(settlement),PGR與IPR的程序都可以隨時終止。自從2012年實施以來,PTAB每年的IPR收案量都相當顯著地成長,如2014年時聲請IPR的案件數共1310件,但2015年度光是上半年,IPR收件數就高達1319件(表1)。
表1:PTAB歷年IPR案件處理狀況統計
資料來源:http://uspto.gov
張亞樵指出,PTAB在累積了數千件的裁判經驗後,發現在IPR的審判程序上有兩點應該進行修正。首先,在實務上,美國許多非專利實施實體(Non-Practice Entity, NPE)會以同一件專利向不同廠商控告侵權,為了反制此類濫訴,遭控告的廠商都會向PTAB申請IPR;如此一來,就會有許多異議人對同樣一件專利申請多方複審,徒增行政上的困擾。PTAB建議的修正方向,就是參考美國民事裁判中的團體訴訟(class action)制度,讓在相近時間內、對於同一件專利提出IPR的異議人加入同一件裁判案,以減輕聲請人以及PTAB的負擔並加快IPR進程。
IPR的利害關係人揭露應給予補正機會
此外,在IPR程序中,聲請人必須在提出聲請時就列齊所有利害關係人(real parties in interest)。張亞樵指出,這一條規定對於「利害關係人」的定義太過於寬廣,以至於每年有許多IPR複審案,就是因為這項缺失而無法成案。他舉例,「如果一家公司把自己的專利分割出來成立一家新公司,這家新公司申請IPR時,母公司要不要列入利害關係人?或者當群創申請IPR時,鴻海算不算他的利害關係人?如果鴻海算,那鴻海旗下的子公司是不是也得全部列出來?」PTAB因此建議,因為利害關係人的認定在每個案例上都不盡相同,只要聲請人不是故意欺瞞,都應該允許其在事後一定期間內補充或修正,以免聲請人的權益因此受損。
不過,張亞樵還是提醒,雖然PTAB的運作相當接近司法審判,但與真正的民事訴訟還是有差距。「美國的民事程序允許中途加入新證據、加入新的原告或被告,但是IPR爭執的就是專利本身的專利性,」張亞樵解釋,在IPR中,獲勝的關鍵其實就是一開始提交給PTAB的書面資料,如果內容不夠充分,後續就很難扳回劣勢;而且,因為參與裁判的APJ都是資深的專利審查官,聲請人也應該有被問及專業技術問題的準備。總而言之,在提出IPR前就把事實以及技術相關資料準備妥當,不過度依賴訴訟技巧,就是在IPR中獲勝的關鍵。
資料來源:
「通訊產業專利趨勢與訴訟分析」研討會會議資料
Report to Congress – Study and Report on the Implementation of the Leahy-Smith America Invents Act, USPTO, Sep. 2015
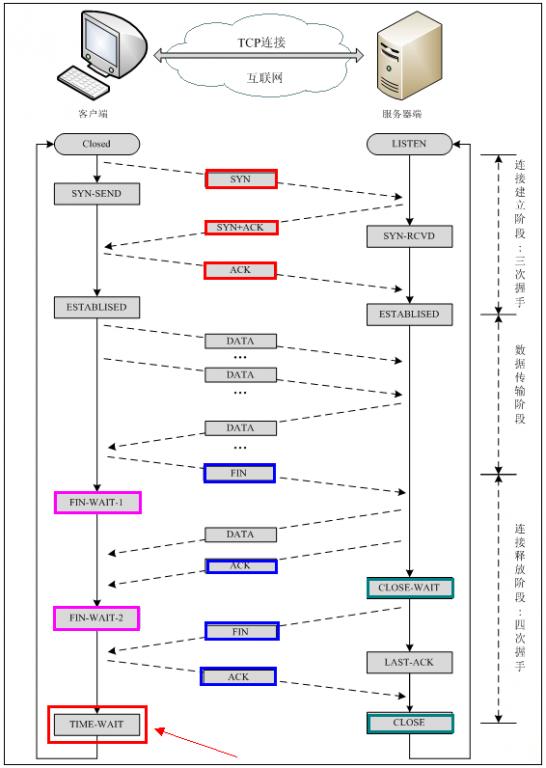
TLS handshake

Rabbit algorithm
Rabbit is a synchronous stream cipher that was rst presented at the Fast
Software Encryption workshop in 2003
The algorithm and source code was released in 2008 as public domain software.
Rabbit was designed by Martin Boesgaard, Mette Vesterager, Thomas Pedersen, Jesper Christiansen and Ove Scavenius.
The authors of the cipher have provided a full set of cryptanalytic white papers on the Cryptico home page.[2] It is also described in RFC 4503
2016年房地产继承税费表一览
http://www.360doc.com/content/16/0311/12/7654794_541292867.shtml
税费税种
编辑
旧版契税
符合住宅小区建筑容积率在1.0(含)以上、
二手房交易税费
二手房交易税费
单套建筑面积在140(含)平方米以下(在120平方米基础上上浮16.7%)、实际成交价低于同级别土地上住房平均交易价格1.2倍以下等三个条件的,视为普通住宅,征收房屋成交价或评估价的1.5%。反之则按3%。
新政下的契税
普通住宅:
卖方:
不满两年(无论是否唯一)6.6%
满两年不满五年(无论是否唯一)1%
满五年唯一住房免税
满五年不唯一住房1%
买方:
购买90平以下房产的1%
购买90平以上房产的(唯一住房)1.5%
购买90平以上房产的(不唯一住房)2%
商业房或公司产权:3%
城市维护建设税
营业税的7%。
教育费附加
营业税的3%。
个人所得税
普通住宅2年之内:{售房收入-购房总额-(营业税+城建税+教育费附加税+印花税)}×20%;2年以上(含)5年以下的普通住宅:(售房收入-购房总额-印花税)×20%。出售公房:5年之内,(售房收入-经济房价款-土地出让金-合理费用)×20%,其中经济房价款=建筑面积×4000元/平方米,土地出让金=1560元/平方米×1%×建筑面积。出售不是家庭唯一住房的个税按房价的1%征收。
交易手续费
2元/平方米×建筑面积
印花税
房屋成交总额×0.05%(2009年至今暂免)
营业税
2011年1月27日新通知规定:个人将购买不足5年的住房对外销售的,全额征收营业税;个人将购买超过5年(含5年)的非普通住房对外销售的,按照其销售收入减去购买房屋的价款后的差额征收营业税;个人将购买超过5年(含5年)的普通住房对外销售的,免征营业税。
(废止)住宅5年内:房屋评估总额×5.6% ;5年或5年以上普通住宅无营业税。
(最新)住宅2年内:房屋评估总额×5.6% ;2年或2年以上普通住宅无营业税。
2015年3月30日财政部、国家税务总局发布《关于调整个人住房转让营业税政策的通知》(财税[2015]39号)规定:“个人将购买不足2年的住房对外销售的,全额征收营业税;个人将购买2年以上(含2年)的非普通住房对外销售的,按照其销售收入减去购买房屋的价款后的差额征收营业税;个人将购买2年以上(含2年)的普通住房对外销售的,免征营业税。”[2]
增值税
自2016年5月1日起,在全国范围内全面推开营业税改证增值税试点,建筑业、房地产业、金融业、生活服务业等全部营业税纳税人,纳入试点范围,由缴纳营业税改为缴纳增值税。《财政部国家税务总局关于全面推开营业税改证增值税试点的通知》(财税[2016]36号)
对于非一线城市,个人购买不足2年的住房对外销售,按照5%的征收率全额缴纳增值税;个人将购买2年以上(含2年)的住房对外销售的,免征增值税。
北、上、广、深四个一线城市,个人购买不足2年的住房对外销售的,按照5%的征收率全额缴纳增值税;个人将购买2年以上(含2年)的非普通住房对外销售的,以销售收入减去购买住房价款后的差额按照5%的征收率缴纳增值税;个人将购买2年以上(含2年)的普通住房对外销售的,免征增值税。
土地增值税
普通住宅免征;非普通住宅3年内:房屋成交总额×0.5% ,3年至5年:房屋成交总额×0.25%,5年或5年以上:免征。
房屋所有权登记费
80元,共有权证:20元
买卖合同公证费
买卖合同需要公证时才须缴纳,房屋成交总额×0.3%;
过户费用
(1)契税:9
卖方:
不满两年(无论是否唯一)6.6%
满两年不满五年(无论是否唯一)1%
满五年唯一住房免税
满五年不唯一住房1%
买方:
购买90平以下房产的1%
购买90平以上房产的(唯一住房)1.5%
购买90平以上房产的(不唯一住房)2%
(2)房屋交易手续费:‘买卖双方各自缴纳房屋建筑面积*2元/平方米
(3)房屋所有权登记费:80元。
(4)房屋评估费;按评估额0.5%缴纳
计算方式
编辑
契税由买方交纳,交税比例是:
1、普通住宅应该交纳成交价或是评估价的1.5%的契税。
2、非普通住宅应该交纳成交价或是评估价的3%的契税。
过户费用;
(1)契税;90平方米以下首次购房的按1%缴纳;90—140平方米按房价1.5%缴纳;140平方米以上按房价3%缴纳买方承担(二套房按3%收取)
(2)营业税:房屋产权取得满五年的免征,未超过五年的按房价5.8%缴纳。卖方承担
(3)土地增值税;房屋产权取得满五年的免征,未超过五年的按房价1%预缴纳,按照超率累进税率计算,多退少补。卖方承担
(4)所得税:房屋产权取得满五年的免征,未超过五年的按房价1%或房屋原值—房屋现值差额20%缴纳。(房屋原值一般按上道契税完税额计算)卖方承担
(5)房屋交易手续费:按房屋建筑面积6元/平方米交纳双方承担
(6)房屋产权登记费:80元。买方承担
(7)房屋评估费:按评估额0.5%
交易手续
编辑
正常过户手续
(一) 交易税费
1.营业税 (税率5.6%, 卖方缴纳)
根据2015年3月房产新政,转让出售购买时间不足2年的非普通住宅按照全额征收营业税,转让出售购买时间超过5年的非普通住宅或者转让出售购买时间不足2年的普通住宅按照两次交易差价征收营业税,转让出售购买时间超过5年的普通住宅免征营业税。
这里有两个要点
①购买时间超过2年这里首先看产权证, 其次看契税发票,再次看票据(房改房看国有住房出售收入专用票据)这三种证件按照时间最早的计算。一般地说票据早于契税发票,契税发票早于产权证,房改房中时间最早的是房改所收的定金的票据。
②所售房产是普通住宅还是非普通住宅。
另:如果所售房产是非住宅类如商铺、写字间或厂房等则不论证是否过5年都需要全额征收营业税。
2. 个人所得税(税率交易总额1%或两次交易差的20%, 卖方缴纳)
征收条件以家庭为单位出售非唯一住房需缴纳个人房转让所得税。在这里有两个条件①家庭唯一住宅②购买时间超过5年。如果两个条件同时满足可以免交个人所得税;任何一个条件不满足都必须缴纳个人所得税。注:如果是家庭唯一住宅但是购买时间不足5年则需要以纳税保证金形式先缴纳,若在一年以内能够重新购买房产并取得产权则可以全部或部分退还纳税保证金,具体退还额度按照两套房产交易价格较低的1%退还。
注:地税局会审核卖方夫妻双方名下是否有其他房产作为家庭唯一住宅的依据,其中包括虽然产权证没有下放但是房管部门已经备案登记的住房(不包含非住宅类房产)。
另注:如果所售房产是非住宅类房产则不管什么情况都要缴纳个人所得税。而且地税局在征税过程中对于营业税缴纳差额的情况,个人所得税也必须征收差额的20% 。
3.印花税(税率1%,买卖双方各半)
从2009年至今暂免征收。
4.契税(税率1%、1.5% 、3%,买方缴纳)
征收方法:按照基准税率征收交易总额的3%,若买方是首次购买面积不足90平的普通住宅缴纳交易总额的1%,若买方首次购买面积超过90平(包含90平)的普通住宅则缴纳交易总额的1.5%。
注:首次购买和普通住宅同时具备才可以享受优惠,契税的优惠是以个人计算的,只要是首次缴契税都可以享受优惠。若买方购买的房产是非普通住宅或者是非住宅则缴纳交易总额的3%。
5.测绘费1.36元/平米 总额=1.36元/平米*实际测绘面积 (2008年4月后新政策房改房测绘费标准:面积75平米以下收200元,75平米以上144平米以下收300元,144平米以上收400元)
一般房改房都是需要测绘的,商品房如果原产权证上没有市房管局的测绘章也是需要测绘的。
6.二手房交易手续费总额:住宅6元/平米×实际测绘面积 非住宅10元/平米×实际测绘面积
7.房屋产权登记费80元 共有权证:20元
(二)所需材料
1.地税局需要卖方夫妻双方身份证和户口本复印件一套(若卖方夫妻不在同一个户口本上还需提供结婚证复印件一套)、买方身份证复印件一套、网签买卖协议一份、房产证复印件一套(如果卖方配偶已经去世还需要派出所的死亡证明一份)
2.房管局需要网签买卖协议一份、房产证原件、新测绘图纸两张,免税证明或完税证明复印件;如省直房改房还需已购公房确认表原件两份和附表一。
注:房改房过户时需要配偶一起出面签字;若配偶已经去世但使用了其工龄,如果是在房改之后则需要先做继承公证再交易过户;如在房改之前,则应提交派出所开具的死亡证明原件。省直房改房还需填写《已购公房确认表》两份并由单位和省直房改办盖章确认,并提交房改原始票据原件。
赠与过户手续
(一)费用:免征营业税和个人所得税,但是需要增加
1.公证费:40元/平米× 产权证面积
2.契税:不论房产什么情况都需要征收全额契税
其他费用和正常过户都一样
(二)所需材料
1.公证处需要卖方夫妻双方户口本和身份证复印件一套、买方身份证复印件一份,产权 证复印件一套
2.不需要经过地税局直接可以过户。
3.房管局需要材料同正常过户基本一样只不过还需要公证书原件一份。
继承房产过户
(一)继承房产的费用有
1.公证费 40元/平米×产权证面积
2.继承公证费 80元/单 放弃继承公证:80元/人
注:继承的房产再次转让出售时个人所得税按照所得征收20%,不过只要是符合家庭唯一住房和购买超过5年的话就可以免征个人所得税,而且个人所得税退税的政策同样适用。
(二)所需材料
1.公证处需要原产权人的死亡证明、产权证复印件和所有当事人的身份证、户口本复印件一套。
2.房管局需要材料和正常过户基本一样,只是还需要公证书一份。
注:继承的难点在于公证所有的继承人都放弃继承,这样就要求证明当事人即为所有继承人并且都自愿放弃继承权。
析产
析产又称财产分析,是指财产共有人通过协议的方式,根据一定的标准,将共同财产予以分割,而分属各共有人所有。最常见的是夫妻之间的析产,一般会有婚内析产和离婚析产两种情况。过程是先到公证处做析产公正再到房管局办理过户手续。除其他材料外还需要离婚协议书或者法院判决书复印件。
注意事项
编辑
房屋手续是否齐全
房产证是证明房主对房屋享有所有权的惟一凭证,没有房产证的房屋交易时对买受人来说有得不到房屋的极大风险。房主可能有房产证而将其抵押或转卖,即使现在没有房产证,过短时间办理取得后,房主还可以抵押和转卖。所以最好选择有房产证的房屋进行交易。
房屋产权是否明晰
有些房屋有好多个共有人,如有继承人共有的、有家庭共有的、还有夫妻共有的,对此买受人应当和全部共有人签订房屋买卖合同。如果只是部分共有人擅自处分共有财产,买受人与其签订的买卖合同未在其他共有人同意的情况下一般是无效的。
交易房屋是否在租
有些二手房在转让时,存在物上负担,即还被别人租赁。如果买受人只看房产证,只注重过户手续,而不注意是否存在租赁时,买受人极有可能得到一个不能及时入住的或使用的房产。因为我国包括大部分国家均认可“买卖不破租赁”,也就是说房屋买卖合同不能对抗在先成立的租赁合同。这一点在实际中被很多买受人及中介公司忽视,也被许多出卖人利用从而引起较多纠纷。
土地情况是否清晰
二手房中买受人应注意土地的使用性质,看是划拨还是出让,划拨的土地一般是无偿使用,政府可无偿收回,出让是房主已缴纳了土地出让金,买受人对房屋享有较完整的权利;还应注意土地的使用年限,如果一个房屋的土地使用权仅有40年,房主已使用十来年,对于买受人来说是否还应该按同地段土地使用权为70年商品房的价格来衡量时,就有点不划算。
市政规划是否影响
有些房主出售二手房可能是已了解该房屋在5到10年左右要面临拆迁,或者房屋附近要建高层住宅,可能影响采光、价格等市政规划情况,才急于出售,作为买受人在购买时应全面了解详细情况。
福利房屋是否合法
房改房、安居工程、经济适用房本身是一种福利性质的政策性住房,在转让时有一定限制,而且这些房屋在土地性质、房屋所有权范围上有一定的国家规定,买受人购买时要避免买卖合同与国家法律冲突。
单位房屋是否侵权
一般单位的房屋有成本价的职工住房,还有标准价的职工住房,二者土地性质均为划拨,转让时应缴纳土地使用费。再者,对于标准价的住房一般单位享有部分产权,职工在转让时,单位享有优先购买权。买受人如果没有注意这些可能会和房主一起侵犯单位的合法权益。
物管费用是否拖欠
有些房主在转让房屋时,其物业费、电费以及三气(天然气、暖气、煤气)费用长期拖欠,且已欠下数目不小的费用,买受人不知情购买了此房屋,所有费用买受人有可能要全部承担。
中介公司是否违规
有些中介公司违规提供中介服务,如在二手房贷款时,为买受人提供零首付的服务,即买受人所支付的全部购房款均可从银行骗贷出来。买受人以为自己占了便宜,岂不知如果被银行发现,所有的责任有可能自己都要承担。
合同约定是否明确
二手房的买卖合同虽然不需像商品房买卖合同那么全面,但对于一些细节问题还应约定清楚,如:合同主体、权利保证、房屋价款、交易方式、违约责任、纠纷解决、签订日期等等问题均应全面考虑。
交易五关
编辑
定价关
二手房买卖最关键的环节就是房屋价格的评估,对于经验不足的业主来说,价格定高了难以找到买主,定低了又会使自己蒙受经济损失。
建议:将房子委托给有资信的中介公司,然后通过市场比较法、收益法、成本法等为客户的房子做出较为公正的评估。较为常见的市场比较法要求评估人有丰富的交易经验,熟悉了解市场价格,并能够根据房屋的位置、朝向、装修程度、房龄等因素对房价做出较为准确的评估。
合同关
近年来,二手房交易双方常常因合同签订得不够规范,导致纠纷事件不断出现。而签订合同常常要注意诸多细节问题,如屋内设施细节、付款方式、交房具体时间、税费交付等等。
建议:如果委托正规中介公司,最后达成了买卖交易,中介公司会提供规范且详实的买卖合同文本,这就为买卖双方减少了很多麻烦,也避免了因合同不规范而引起的纠纷。随后,卖方要结清所有物业费和供暖费,为下一环节立契过户做好准备。
过户关
办理房屋的立契过户,是买卖流程中最耗时间和精力的一关。办理过户涉及一系列的政策法规,手续繁琐。购房者由于缺乏房地产交易知识,没有相关经验,不了解有关部门的办事程序,往往跑断了腿,事情也办不圆满,花费了大量的人力、财力。
建议:一些正规的中介公司可以代办过户,其办证部门的办事人员通晓有关的政策法规和办事程序,经验丰富。因此,委托专业的中介公司办理房产过户,省时、省力、省心,是多数消费者的首选。
付款关
付房款是客户最为担心的一个环节,少则十几万,多则几十万的房款,一旦出了问题,购房者将蒙受巨大的损失。在房屋买卖中,确实存在着房产交割的风险。买方担心把钱交给卖方而产权过户中如出现问题,会拿不到产权证;卖方担心产权证办到了买方名下,买方拖欠房款。
建议:针对上述情况,一些大型正规中介公司纷纷推出“居间中保”服务,买方把房款交给中介公司保管,卖方把原产权证交中介公司保管,中介为双方办理产权过户,新产权证拿到后,中介一手把房款付给卖方,一手把新产权证交给买方,从而确保了双方的利益。
交验关
物业交验是买卖交易的最后一个环节,如果能够顺利完成,客户随即可以安心入住,原业主也不再对房子负有责任了。
建议:物业交验时,中介公司会提供一份《物业交验单》供买卖双方填写确认。验房的内容主要包括:物业是否与合同约定的一致;所售房屋里的家具等是否已搬空;钥匙是否已交付;水电费、煤气费、电话费、有线收视费等杂费是否已经结清等。
税费规定
编辑
2013年税费规定
二套房贷款首付比例可提高
继续严格实施差别化住房信贷政策。对房价上涨过快的城市,人民银行当地分支机构可根据城市人民政府新建商品住房价格控制目标和政策要求,进一步提高第二套住房贷款的首付款比例和贷款利率。
对出售自有住房按规定应征收的个人所得税,通过税收征管、房屋登记等历史信息能核实房屋原值的,应依法严格按转让所得的20%计征。
地级市“十二五”末联网住房信息
通知还要求,市、县人民政府应于一季度公布年度住房用地供应计划。2013年底前,地级以上城市要把符合条件的、有稳定就业的外来务工人员纳入当地住房保障范围。大力推进城镇个人住房信息系统建设,到“十二五”期末,所有地级以上城市原则上要实现联网。加快建立和完善引导房地产市场健康发展的长效机制。
150万房价个税多缴24万
来京工作6年的吴先生刚缴纳购房定金,但因二手房购房政策的调整,他可能要面临多缴纳20多万个税的情况。
在北京,购买二手房所有税费均由购房者承担。例如,吴先生在朝阳区购买了一套价值150万的小户型二类经济适用房,该房已满五年可上市交易,但并非业主的唯一住房。
按现行政策,吴先生需替业主缴纳总房价1%的个人所得税,即150×1%=1.5万元;但是,如果按照新政策,因该经济适用房最初价值仅为20万元,如果按照差额缴税即(150-20)×20%=26万。
这多出的24万多元的税收,让吴先生很头疼。他说,他购买的这套小户型用于自住,但现在,多出的20万限制住了他这种非投资者。吴先生希望,政策应该进行细化,对于非投资性的住房,应给予个人所得税减免或返还。
本次调控时间表
●各直辖市、计划单列市和省会城市(除拉萨外),要按照保持房价基本稳定的原则,制定本地区年度新建商品住房(不含保障性住房)价格控制目标,并于一季度向社会公布。
●市、县人民政府应于一季度公布年度住房用地供应计划。
●2013年底前,地级以上城市要把符合条件的、有稳定就业的外来务工人员纳入当地住房保障范围。
●大力推进城镇个人住房信息系统建设,到“十二五”期末,所有地级以上城市原则上要实现联网。
■ 北京落地
■ 解读
政策2
二套房可实施差别化信贷
对房价上涨过快的城市,人民银行当地分支机构可根据政策要求,进一步提高第二套住房贷款的首付款比例和贷款利率。
近期,二套房贷首付将调至7成,利率增至1.3倍的传言甚嚣。昨天公布的通知中,并未明确二手房贷的具体政策,但提出可进一步提高。
陈志和胡景晖均认为,各地应该会从实际情况出发,来确定二套房的政策,除了继续收紧外,国家也明确提出鼓励改善性购房需求,因此对于二套房也不能一棒子打死。同时,也要看当地银行自身的情况。
“如果真是调到7成,那和全款购房也没太多差别了。”胡景晖认为,二套房也应该实施差别化信贷政策,如果二套房购买的是普通住房,则不应该再上调。
政策3
限购政策全覆盖
限购区域应覆盖城市全部行政区域。
陈志认为,限购要覆盖城市的全部行政区域是细则非常严厉的条款。此前,一些经济发达城市限购,但其周边区域却不限购,这导致那些投资投机的购房仍然有空间,也导致了这些不限购区域的房价出现快速上涨。而此次新一轮调控中,明确了限购的城市要覆盖城市的全部行政区域。
“经济发达城市的周边,比如北京周边的香河、涿州等地,以及上海、杭州等城市周边,按照政策也应该要实行限购。这样就堵住了所有的漏洞,让投资投机购房完全没有市场,住房也彻底回归自住的属性。”陈志说。
不同类型房应区别对待
胡景晖说,以前的房改房、经适房,当时的购买价格只有两三千甚至几百元每平米,而如今的卖出价已经高达数万元,这就意味着几乎是全部交易额的20%来征税。
胡景晖说,“再加上营业税、契税等,买一套300万的房子,税费要八九十万。”他认为,北京出台的调控落地细则中,应该要根据房屋的不同性质来区别税收政策。
税费谁交
编辑
买卖房屋的税收,国家列明买卖双方各自应承担的费用标准,各项费用应由谁承担清晰可见,购房的承担其自身的购房交易税费,卖房的承担其自身通过出售房屋所得收益应缴纳的税费;但自2006年国家出台“国十五条”,其中规定,“从2006年6月1日起,对购买住房不足5年转手交易,销售时按其取得的售房收入全额征收营业税”。
按国家相关部门规定,个人所得税、营业税及土地增值税、教育附加费均是卖方支付的,前二者是房屋卖出所产生,而卖方就是所得者,所以,这以上税费由卖方支付才是合理的。但这几个税费所占比例较大,就成了卖方定价的一个重要标准。因此,很多卖家相应降低房价,搞一刀切,净收房价,所有税费由买方负责了。不过生意场上,一个愿打一个愿挨,当各自认为物有所值时,买卖就成功了。
税费由谁交的问题,实际上国家有明文规定,全由买家交原则上说是不合理的。但实际上税费与房价是相互关联的,如果卖家交税费,那么房价可能就高一些,买家交税费,房价就相对低一些。合同中约定由谁交税费是符合民法上自治原则的,从这个角度讲税费由买家交也是合理的
Top Domain
Open Source UDP File Transfer Tool Comparison
Open Source UDP File Transfer Tool Comparison
February 3, 2016 Michael C 0 Comments
When it comes to Internet protocols, TCP has been the dominant protocol used across the web to form connections. TCP helps computers communicate by breaking large data sets into individual packets, transmitting them, and then reforming the packet in the original order once the data set has been received. But as file sizes grew and latency became an issue, User Datagram Protocol (UDP), gained more popularity. UDP picks up the slack by offering faster speeds with the ability to transmit much larger files, something that TCP isn’t capable of.
When comparing the architecture of the two protocol tools, the main difference is that UDP sends the packets without waiting for each connection to go through, which means lower bandwidth overhead and latency. TCP, on the other hand, sends the packets one at a time, in order, waiting to make sure each connection goes through before starting the next. To better understand the pros and cons of each protocol, below is a basic comparison of the two:
Feature
TCP UDP
Connection Connection-Oriented: messages navigate the internet one connection at a time Connectionless: a single program sends out a load of packets all at once.
Usage Used for application needing high reliability, where time is less relevant Used when applications need fast transmission
Used by other protocols HTTP, HTTPS, FTP, SMTP, Telnet DNS, DHCP, TFTP, SNMP, RIP, VOIP
Reliability All transferred data is guaranteed to arrive in order specified. No guarantee of arrival and ordering has to be managed by the application layer
Header Size 20 bytes 8 bytes
Data Flow Control Does flow control, requiring three packets to set up a socket connection before user data can be sent Does not have an option for flow control
Error Checking Yes Yes, but no recovery options
Acknowledgments Yes, required before next transfer will take place No, allows for quicker speed
There’s a clear tradeoff between the two when it comes to speed versus reliability, but as developments have been made with UDP, it’s become more and more trustworthy as a leading protocol tool. Recently, Google announced that they use their open source Google QUIC UDP-based protocol to run 50% of their Chrome traffic, with that percentage expecting to increase in the coming years. So as the market shifts and advancements continue to be made with the source code, UDP is quickly becoming the file transfer tool of the future. So what UDP should you use?
Choosing a UDP
When it comes to choosing a UDP there are two main options—buy it from a commercial service or install it for open source software. Given the immaturity of most open source software, it may not be as user friendly, but there are many options out there, so paying developers to manage and configure your UDP is not necessary.
Currently, there are six main UDP file transfer tools available as open source.
Tsunami UDP Protocol: Uses TCP control and UDP data for transfer over high speed long distance networks. It was designed specifically to offer more throughput than possible with TCP over the same networks.
UDT UDP-based Data Transfer: Designed to support global data transfer of terabyte sized data sets, using UDP to transfer the bulk of its data with reliability control mechanisms.
Enet: Main goal is to provide a thin, simple and robust network communication layer on top of UDP with reliable and ordered delivery of packets, which they accomplish by stripping it of higher level networking features.
UFTP: Specializes in distributing large files to a large number of receivers, especially when data distribution takes place over a satellite link, making TCP communication inefficient due to the delay. They have been used widely by The Wall Street Journal to send WSJ pages over satellite to their remote printing plants.
GridFTP: Unlike all others, GridFTP is based on FTP and is not UDP, but it can be used to solve the same problems experienced when using TCP.
Google QUIC: An experimental UDP-based network protocol designed at Google to support multiplexed connections between two endpoints, provide security protection equivalent to TSL/SSL, and reduce latency and bandwidth usage.
Below is a features comparison chart to better help you understand the side by side differences each system supports.
Tsunami
UDT
ENet
UFTP
GridFTP
Google QUIC
Multi-Threaded No No Yes No Yes Yes
Protocol Overhead 20% 10% NA ~10% 6-8%, same as TCP NA
Encryption No No No Yes Yes Yes
C++ source code Yes Yes Yes Yes Yes Yes
Java Source Code No Partial No No No No
Command Line No No No Yes Yes Yes
Distribution Packets Source code only Source code only Source Only Yes Yes Yes
UDP based point-to-point Yes Yes Yes Yes No Yes
Firewall Friendly No Partial, no auto-detection No Partial, no auto-detection No No, has had issues with stateful firewalls
Congestion Control Yes Yes NA Yes Yes, using TCP Yes
Automatic retry and resume No No Yes No, manual resume yes Yes Yes
Jumbo Packets No Yes No Yes, up to 8800 bytes Yes NA
Support for Packet Loss No No Yes No Yes Yes
Conclusion
When deciding what UDP tool to use, you have several factors to keep in mind. Many of issues arise when dealing with packet loss and recovery. For instance, UDT has been known to fail completely if even the slightest packet loss is reported, whereas Google QUIC has made significant advancements in addressing this issue. GridFTP might also not be the most user friendly, since it requires a much larger framework and orchestration to run, since it is not UDP-based. Considering all these factors intandem, hopefully you’ll be able to make a more informed decision when implementing UDP file transfer tools on your network.
SSL 3.0 POODLE
SSL/TLS协议的演化 10–安全问题 – SSLv3的POODLE攻击
发表回复
image
1.有趣的POODLE
POODLE是Padding Oracle On Downgraded Legacy Encryption的缩写,不知是巧合还是有意,在英文中Poodle的意思是贵宾犬,于是老外在写POODLE攻击相关文字的时候,用这种漂亮的小狗做配图。给人的感觉是,这小狗是SSL的吉祥物。
老外的一个习惯就是,无论做什么项目,都要事先起一个响亮的名字(伽利略计划之类)或者搞一个缩写(就像SSL)。POODLE既是缩写又是靓名,很容易就扬名天下了。这一招我们很快就学会了,例如百度凤巢的。
POODLE攻击是Google的研究员14年9月发现的,算是新攻击了,文档是【POODLE】。攻击的研究者也是2011年BEAST攻击的发现者。POODLE仅仅针对SSLv3,但它本质上和BEAST攻击很类似:
1.针对CBC模式块加密的缺陷。
2.目的是恢复cookie中的敏感信息
3.猜测的方式是一个byte一个byte的选择明文注入。
4.降维打击:利用POODLE缺陷,猜测n个byte需要发送的探测次数是O(n),即每个n byte需要256*n次。如果没有这种缺陷,仅仅bruteforce方式猜测,需要2^(8*n)次。
但操作更简单,而且没有像BEAST那样的workaround,只能升级协议。
2.攻击原理
POODLE仅仅针对SSLv3,而对TLS1.0无效,利用SSLv3加密块的Padding是随机值这一协议设计缺陷。
RFC6101 SSLv3的5.2.3.2定义了CBC块加密下的SSLv3加密块定义:
block-ciphered struct {
opaque content[SSLCompressed.length];
opaque MAC[CipherSpec.hash_size];————————————->1.对Padding部分没有完整性保护,这里MAC保护content,content length,sequence number。
uint8 padding[GenericBlockCipher.padding_length];————–>2.padding是随机的。看起来更不容被猜测到,实际上画蛇添足了。随机加上没有完整性保护,意味着无论这部分数据是什么内容,接收方都不会在意。
uint8 padding_length;
} GenericBlockCipher;
下面是一个可能的HTTP Post明文格式的例子,标为蓝色的path和body是上层应用或者说攻击者可以控制的数据:
“POS T /path C o o ki e : name=value… \ r\ n\ r\ nbody ‖ 20byte MAC ‖ padding”
假定加密后得到如下加密快,C1,C2到Cn,(C0是IV我们看不到),对于第i个加密块,处理的流程如下:
1.Pi = Dk(Ci) ⊕ Ci-1 –>其中k是密钥,Dk是解密函数,Pi是解密后的明文。
2.检查并移除Pn尾部的padding(Pn也可以完全是padding)。
3.检测并移除MAC,得到了明文。
攻击者希望通过选择明文注入,达到如下两个效果:
1.通过调整“path”的长度,使得cookie中尚未被猜测出来的字节位于上一个块的尾部(假设包括这个字节的加密块是Ci)。
2.然后调整“body”的长度,使得最后一个块(Cn)都是padding(也就是整个Post长度是block的整数倍)。
这显然是可以做到的。
之后攻击者保存Ci,替换最后的Cn,发送到Server。假设padding是随机填充的,只要计算之后最后一个字节碰撞成功,则整个报文可以正确发送出去。假设每个block是16字节,最后一个字节是Ci[15]。则
Dk(Ci)[15] ⊕ Cn-1[15] = 15 /*15是padding length*/
又根据前面的公式:
Pi = Dk(Ci) ⊕ Ci-1
则
15 ⊕ Cn1[15] ⊕ Ci-1[15] = Cn1[15] ⊕ Ci-1[15] ⊕ Dk(Ci)[15] ⊕ Cn-1[15] = Ci-1[15] ⊕ Dk(Ci)[15] = Pi[15]
—->这样就解出来最后一个字节
这里因为并不能保证每个数值尝试一次,只能说统计学上讲,256次尝试之后,会碰上一次。
3.防范措施 – TLS SCVS
定义了一个空的加密套件TLS_FALLBACK_SCSV {0x56, 0x00},如果Client这次用的版本号低于自己最高支持的版本好,必须携带这个信令。Client利用这个标记告诉Server,我因为上次连接失败,被你要求版本了。Server如果发现,自己没有降低Client的版本,则一定有中间人攻击,人为降低了前面Client发送的版本好,试图攻击。
什么时候这个扩展不管用:
1.有一方确实最高仅仅支持SSLv3。
2.有一方不支持这个扩展。
看到这种方法,我的第一反应是,如果中间人从两边的协商中全部剥离这个信令怎么办?后来想明白了,前几天被我认为狗血的Session Hash,这里起作用了。因为它检查所有发出去的握手报文的完整性,中间人无法欺骗了(待确认)。
还有一个问题是为什么不用标准扩展方式而用了一个特殊的加密套件这种Tricky的手段,后来也想明白了,TLS对这种攻击免疫,因此必须要SSLv3支持这种扩展,而又不能修改已有的SSLv3实现,用特殊加密套件这种方式来实现最少代码升级的扩展。
4.为什么TLS1.0可以免疫
我们看看TLS1.0协议的那一部分的改动解决了这个问题
RFC2246 TLS1.0里面相关数据结构没有变化,MAC依然无法保护padding,但是padding的内容有了规定:
“Each uint8 in the padding data vector must be filled with the padding length value.”
也就是,padding部分被填充成为padding length的值。假设padding有7byte,则连同padding length的8个bytes的内容是“7,7,7,7,7,7,7,7”,这样替换padding内容会被发现,攻击强度等同于暴力破解。
【参考】
1.POODLE, https://www.openssl.org/~bodo/ssl-poodle.pdf
2.BEAST,火狐浏览器分割HTTPS报文的问题,http://www.unclekevin.org/?p=38
3.TLS SCVS – TLS Fallback Signaling Cipher Suite Value (SCSV) for Preventing Protocol Downgrade Attacks,draft-ietf-tls-downgrade-scsv-05,https://datatracker.ietf.org/doc/draft-ietf-tls-downgrade-scsv/?include_text=1
本条目发布于2015年3月6日。属于SSL/TLS、安全、网络协议分类。
http://support.fortinet.com.cn/uploadfile/2015/0513/20150513020838240.pdf
SSL 3.0 POODLE SSL 3.0 POODLE SSL 3.0 POODLESSL 3.0 POODLE SSL 3.0 POODLE SSL 3.0 POODLE 漏洞
版本
1.0
时间
2015年4月
作者
张彦龙 (ylzhang@fortinet.com)
受影响的版本
FortiOS (4.3.X, 5.0.X, 5.2.X)
状态
草稿
1. 简介
1.1 SSL 3.0 poodle漏洞介绍
2014年10月15日,Google研究人员公布SSL 3.0协议存在一个非常严重的漏洞,该漏洞可被黑客用于截取浏览器与服务器之间进行传输的加密数据,如网银账号、邮箱账号、个人隐私等等。SSL 3.0的漏洞允许攻击者发起降级攻击,即欺骗浏览器说“服务器不支持更安全的安全传输层(TLS)协议”,然后强制其转向使用SSL 3.0,在强制浏览器采用SSL 3.0与服务器进行通讯之后,黑客就可以利用中间人攻击来解密HTTPs的cookies,Google将其称之为POODLE攻击,若受到POODLE 攻击,所有在网络上传输的数据将不再加密。目前已被TLS 1.0,TLS 1.1,TLS 1.2替代,因为兼容性原因,大多数的TLS实现依然兼容SSL3.0。
1.2 SSL 3.0 poodle攻击原理
为了通用性的考虑,目前多数浏览器版本都支持SSL3.0,TLS协议的握手阶段包含了版本协商步骤,一般来说,客户端和服务器端的最新的协议版本将会被使用。其在与服务器端的握手阶段进行版本协商的时,首先提供其所支持协议的最新版本,若该握手失败,则尝试以较旧的协议版本协商。能够实施中间人 攻击的攻击者通过使受影响版本浏览器与服务器端使用较新协议的协商的连接失败,可以成功实现降级攻击,从而使得客户端与服务器端使用不安全的SSL3.0 进行通信,此时,由于SSL 3.0使用的CBC块加密的实现存在漏洞,攻击者可以成功破解SSL连接的加密信息,比如获取用户cookie数据。这种攻击被称为POODL攻击 (Padding Oracle On Downgraded Legacy Encryption)。 此漏洞影响绝大多数SSL服务器和客户端,影响范围广泛。但攻击者如要利用成功,需要能够控制客户端和服务器之间的数据(执行中间人攻击)。通常用户的浏览器都使用新版本的安全协议与服务器进行连接,为了保持兼容性,当浏览器安全协议连接失败的时候, 就会转而尝试老版本的安全协议进行连接,其中就包括SSL 3.0。Poodle攻击的原理,就是黑客故意制造安全协议连接失败的情况,触发浏览器的降级使用 SSL 3.0,然后使用特殊的手段,从 SSL 3.0 覆盖的安全连接下提取到一定字节长度的隐私信息。
1.3 SSL协议要点
SSL协议由美国 NetScape公司开发的, 1996年发布了V3.0版本。SSL 3.0 已经存在 15 年之久,目前绝大多数浏览器都支持该版本。SSL3.0是已过时且不安全
的协议,SSL(Secure Sockets Layer 安全套接层)是一种基于Web应用的安全通信协议。 SSL介于TCP协议和应用层协议之间,主要作用就是将HTTP、FTP等应用层的数据进行加密然后依托可靠的TCP协议在互联网上传输到目的地,其中最典型的应用就是https。
1.4 SSL提供3个基本的安全服务:
1)身份合法性:数据发送方和接收方要确认彼此身份,要确保各自的身份不会被冒充。
2)数据机密性:所有传输的数据都进行加密,并且要确保即使数据被截获也无法破解。
3)数据完整性:确保收到的数据与发送方发出的数据一致,没有被篡改。
1.5 SSL协议主要采用的数据加密算法:
1)非对称加密算法:数据加密和解密使用不同的密钥,如RSA公钥加密算法。优点是安全级别高,很难被破解;缺点是加密解密的速度慢,因此只适用于小量数据的加密。SSL协议采用非对称加密算法实现数字签名,验证数据发送方(或接收方)的身份,同时也用非对称加密算法交换密钥(用于数据加密的对称加密算法的密钥,以及用于数据完整性验证的MAC算法)。
2)对称加密算法:数据加密和解密使用同一个密钥,如DES、3DES、RC4等都是对称加密算法。优点是加解密速度快,适用于大数据量的加密,但安全性较差。SSL协议采用对称加密算法对传输的数据进行加密。
3)MAC算法:Message Authentication Codes,即消息认证码算法,MAC含有密钥散列函数算法,兼容了MD和SHA算法的特性,并在此基础上加入了密钥。SSL协议采用MAC算法来检验消息的完整性。