-
HP Flash Media Kit Spec
HPE Dual 8GB microSD Enterprise Midline USB Kit
741279-B21
Usable Capacity 8GB
Performance 43+ MB/second Read Transfer Rate,43+ MB/second Write Transfer Rate
Class Class 10HPE 8GB USB Enterprise Mainstream Flash Media Drive Key Kit
737953-B21
Usable Capacity 8GB
Performance 20+ MB/second Read Transfer Rate,17 10+ MB/second Write Transfer Rate
Compliance USB specification revision 1.1 and 2.0HPE 8GB SD EM Flash Media Kit
726113-B21
Usable Capacity 8GB
Performance 21+ MB/second Read Transfer Rate,17+ MB/second Write Transfer Rate
Class Class 10HPE 8GB microSD EM Flash Media Kit
726116-B21
Usable Capacity 8GB
Performance 21+ MB/second Read Transfer Rate,17+ MB/second Write Transfer Rate
Class Class 10HPE 32GB SD Enterprise Mainstream Flash Media Kit
700136-B21
Usable Capacity 32GB
Performance 21+ MB/second Read Transfer Rate,17+ MB/second Write Transfer Rate
Class Class 10HPE 32GB microSD Enterprise Mainstream Flash Media Kit
700139-B21
Usable Capacity 32GB
Performance 21+ MB/second Read Transfer Rate,17+ MB/second Write Transfer Rate
Class Class 10 -
Understanding Flash: Unpredictable Write Performance
https://flashdba.com/2014/12/10/understanding-flash-unpredictable-write-performance/
December 10, 2014 6 Comments

I’ve spent a lot of time in this blog series talking about the challenges involved in using flash, such as the way that pages have to be erased before they are written and the restriction that erase operations take place on a whole block. I also described the problem of erase operations being slow in comparison to reads and writes – and the resulting processes we have to put in place to manage that problem (i.e. garbage collection) . And most recently I covered the way that garbage collection can result in unpredictable performance.
But so far we’ve always worked under the assumption that reads and writes to NAND flash have the same predictably low latency. This post is all about bursting that particular bubble…
Programming NAND Flash: A Quick Recap
You might remember from my post on the subject of SLC, MLC and TLC that I used the analogy of electrons in a bucket to explain the programming of NAND flash cells:

I’d now like to change that analogy slightly, so I’m asking you to consider that you have an empty bucket and a powerful hose pipe. You can turn the hose on and off whenever you want to fill the bucket up, but you cannot empty water out of the bucket unless you completely empty it. Ok, now we’re ready.
For SLC we simply say that an empty bucket denotes a binary value of 1 and a full bucket denotes binary 0. Thus when you want to program an SLC bucket you simply let rip with your hose pipe until it’s full. No need to measure whether the water line is above or below the halfway point (the threshold), just go crazy. Blam! That was quick, wasn’t it?
For MLC however, we have three thresholds – and again we start with the bucket empty (denoting binary 11). Now, if I want to program the binary values of 01 or 10 in the above diagram I need to be careful, because if I overfill I cannot go backwards.
 I therefore have to fill a little, test, fill some more, test and so on. It’s actually kind of tricky – and it’s one of the reasons that MLC is both slower than SLC and has a lower wear limit. But here’s the thing… if I want to program my MLC to have a value of binary 00 in the above diagram, I have no such problems because (as with SLC) I can just open the hose up on full power and hit it.
I therefore have to fill a little, test, fill some more, test and so on. It’s actually kind of tricky – and it’s one of the reasons that MLC is both slower than SLC and has a lower wear limit. But here’s the thing… if I want to program my MLC to have a value of binary 00 in the above diagram, I have no such problems because (as with SLC) I can just open the hose up on full power and hit it.What we’ve demonstrated here is that programming a full charge value to an MLC cell is faster than programming any of the other available values. With a little more thought you can probably see that TLC has this problem to an even worse degree – imagine how accurate you need to be with that hose when you have seven thresholds to consider!
One final thought. We read and write (program) to NAND flash at the page level, which means we are accessing a large collection of cells as if they are one single unit. What are the chances that when we write a page we will want every cell to be programmed to full charge? I’d say extremely low. So even if some cells are programmed “the fast way”, just one “slow” program operation to a non-full-charge threshold will slow the whole program operation down. In other words, I can hardly ever take advantage of the faster latency experienced by full charge operations.
Fast Pages and Slow Pages
The majority of flash seen in the data centre today is MLC, which contains two bits per cell. Is there a way to program MLC in order that, at least sometimes, I can program at the faster speeds of a full-charge operation?
 Let’s take my MLC bucket diagram from above and remap the binary values like the diagram on the left. What have I changed? Well most importantly I’ve reordered the binary values that correspond to each voltage level; empty charge still represents 11 but now full charge represents 10. Why did I do that?
Let’s take my MLC bucket diagram from above and remap the binary values like the diagram on the left. What have I changed? Well most importantly I’ve reordered the binary values that correspond to each voltage level; empty charge still represents 11 but now full charge represents 10. Why did I do that?The clue is the dotted line separating the most significant bit (MSB) and the least significant bit (LSB) of each value. Let’s consider two NAND flash pages, each comprising many cells. Now, instead of having both bits from each MLC cell used for a single page, I will put all of the MSB values into one page and call that the slow page. Then I’ll take all of the LSB values and put that into the other page and call that the fast page.
Why did I do this? Well, consider what happens when I want to program my fast page: in the diagram you can see that it’s possible to turn the LSB value from one to zero by programming it to either of the two higher thresholds… including the full charge threshold. In fact, if you forget about the MSB side for a second, the LSB side very similar to an SLC cell – and therefore performs like one.
The slow page, meanwhile, has to be programmed just like we discussed previously and therefore sees no benefit from this configuration. What’s more, if I want to program the fast page in this way I can’t store data in the corresponding slow page (the one with the matching MSBs) because every time I program a full charge to this cell the MSB ends up with a value of one. Also, when I want to program the slow page I have to erase the whole block first and then program both pages together (slowly!).
It’s kind of complicated… but potentially we now have the option to program certain MLC pages using a faster operation, with the trade-off that other pages will be affected as a result.
Getting To The Point
I should point out here that this is pretty low-level stuff which requires direct access to NAND flash (rather than via an SSD for example). It may also require a working relationship with the flash manufacturer. So why am I mentioning it here?
Well first of all I want to show you that NAND flash is actually a difficult and unpredictable medium on which to store data – unless you truly understand how it works and make allowances for its behaviour.
 This is one of the reasons why so many flash products exist on the market with completely differing performance characteristics.
This is one of the reasons why so many flash products exist on the market with completely differing performance characteristics.When you look at the datasheet for an MLC flash product and you see write / program times shown as, for example, 1.4 milliseconds it’s important to realise that this is the average of its bi-modal behaviour. Fast (LSB) pages may well have program times of 300 microseconds, while slow (MSB) pages might take up to 2.5 milliseconds.
Secondly, I want to point out that direct access to the flash (instead of via an SSD) brings certain benefits. What if, in my all flash array, I send all inbound user writes to fast pages but then, later on during garbage collection, I move data to be stored in slow pages? If I could do that, I’d effectively be hiding much of the slower performance of MLC writes from my users. And that would be a wonderful thing…
…which is why, at Violin, we’ve been doing it for years

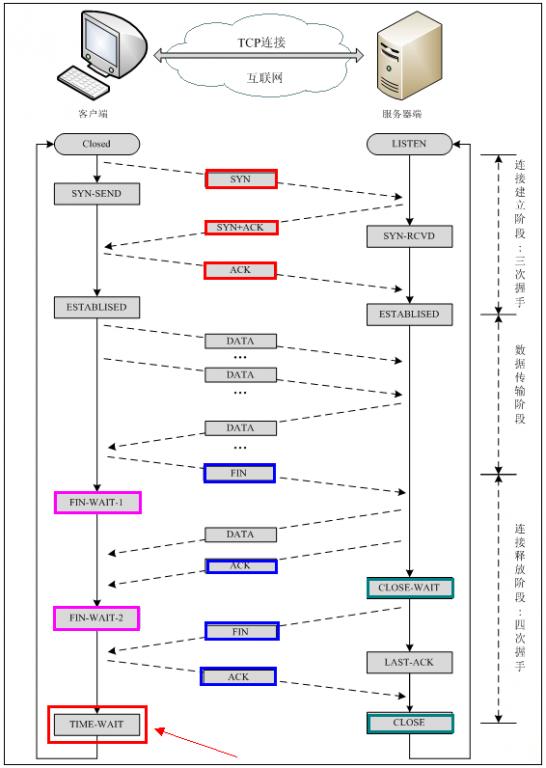
-
SD Card Bug of iLO4 2.4.0/2.4.4
ISSUE:
Upgrade to iLO4 2.4.0 (SPP 2016040), found The server was failed to boot ESX from SD Card. The same issue existed in iLO4 2.4.4
Root Cause:
iLO4 2.4.x will damage the partition table of SD Card/USB Flash,Not Clear it is damaged during the executing phase or stopping phase
Solution :
Rollback iLO4 to 2.3.0 (SPP 2015100)
Create USB Key of SPP 2015100
Boot with the USB
Downgrade the iLO4 firmware with interactive method
Reformat the SD Card/USB Flash
Retrieve the SD Card from server
Format it into empty status in PC (Linux)
Delete the partition table
Create DOS partition table
Create a DOS partition (0x0b)
Format the DOS partition
Insert the empty SD Card into Gen8Reinstall ESX into SD Card
Format the SD Card with FAT32Power outage of the server Lauch iOL remote console Insert CD of ESX iso image file Reboot with CD to install ESX
Lessons
Never trust a Company not in stable state
How to format Micro SD Card in MicroServer Gen8:
Download gparted live CD at
http://downloads.sourceforge.net/gparted/gparted-live-0.26.1-5-i686.iso
And Launch it from iLO client
-
RBICL
RIBCL
Remote Insight Board Command Language
An XML-based scripting language, used to configure iLO on the network, during initial deployment, or from an already iLO setup deployed host.
Two basic ways in order to configure iLO online:
-
Locally, with the HPONCFG command utility.
-
Remotely, with the CPQLOCFG command utility
-
-
Update iLO4 firmware of HP ML Gen8
- Download iLO4 software of window x64 from HPE website
- Extract the download exe file, get the bin file
- Login to iLO4 from browser
- Update iLO4 firmware by uploading the bin file
-
转:Linux上Core Dump文件的形成和分析
Core,又称之为Core Dump文件,是Unix/Linux操作系统的一种机制,对于线上服务而言,Core令人闻之色变,因为出Core的过程意味着服务暂时不能正常响应,需要恢复,并且随着吐Core进程的内存空间越大,此过程可能持续很长一段时间(例如当进程占用60G+以上内存时,完整Core文件需要15分钟才能完全写到磁盘上),这期间产生的流量损失,不可估量。
凡事皆有两面性,OS在出Core的同时,虽然会终止掉当前进程,但是也会保留下第一手的现场数据,OS仿佛是一架被按下快门的相机,而照片就是产出的Core文件。里面含有当进程被终止时内存、CPU寄存器等信息,可以供后续开发人员进行调试。
关于Core产生的原因很多,比如过去一些Unix的版本不支持现代Linux上这种GDB直接附着到进程上进行调试的机制,需要先向进程发送终止信号,然后用工具阅读core文件。在Linux上,我们就可以使用kill向一个指定的进程发送信号或者使用gcore命令来使其主动出Core并退出。如果从浅层次的原因上来讲,出Core意味着当前进程存在BUG,需要程序员修复。从深层次的原因上讲,是当前进程触犯了某些OS层级的保护机制,逼迫OS向当前进程发送诸如SIGSEGV(即signal 11)之类的信号, 例如访问空指针或数组越界出Core,实际上是触犯了OS的内存管理,访问了非当前进程的内存空间,OS需要通过出Core来进行警示,这就好像一个人身体内存在病毒,免疫系统就会通过发热来警示,并导致人体发烧是一个道理(有意思的是,并不是每次数组越界都会出Core,这和OS的内存管理中虚拟页面分配大小和边界有关,即使不出Core,也很有可能读到脏数据,引起后续程序行为紊乱,这是一种很难追查的BUG)。
说了这些,似乎感觉Core很强势,让人感觉缺乏控制力,其实不然。控制Core产生的行为和方式,有两个途径:
1.修改/proc/sys/kernel/core_pattern文件,此文件用于控制Core文件产生的文件名,默认情况下,此文件内容只有一行内容:“core”,此文件支持定制,一般使用%配合不同的字符,这里罗列几种:
%p 出Core进程的PID
%u 出Core进程的UID
%s 造成Core的signal号
%t 出Core的时间,从1970-01-0100:00:00开始的秒数
%e 出Core进程对应的可执行文件名
2.Ulimit –C命令,此命令可以显示当前OS对于Core文件大小的限制,如果为0,则表示不允许产生Core文件。如果想进行修改,可以使用:
Ulimit –cn
其中n为数字,表示允许Core文件体积的最大值,单位为Kb,如果想设为无限大,可以执行:
Ulimit -cunlimited
产生了Core文件之后,就是如何查看Core文件,并确定问题所在,进行修复。为此,我们不妨先来看看Core文件的格式,多了解一些Core文件。
首先可以明确一点,Core文件的格式ELF格式,这一点可以通过使用readelf -h命令来证实,如下图:
从读出来的ELF头信息可以看到,此文件类型为Core文件,那么readelf是如何得知的呢?可以从下面的数据结构中窥得一二:
其中当值为4的时候,表示当前文件为Core文件。如此,整个过程就很清楚了。
了解了这些之后,我们来看看如何阅读Core文件,并从中追查BUG。在Linux下,一般读取Core的命令为:
gdb exec_file core_file
使用GDB,先从可执行文件中读取符号表信息,然后读取Core文件。如果不与可执行文件搅合在一起可以吗?答案是不行,因为Core文件中没有符号表信息,无法进行调试,可以使用如下命令来验证:
Objdump –x core_file | tail
我们看到如下两行信息:
SYMBOL TABLE:
no symbols
表明当前的ELF格式文件中没有符号表信息。
为了解释如何看Core中信息,我们来举一个简单的例子:
#include “stdio.h”
int main(){
int stack_of[100000000];
int b=1;
int* a;
*a=b;
}
这段程序使用gcc –g a.c –o a进行编译,运行后直接会Core掉,使用gdb a core_file查看栈信息,可见其Core在了这行代码:
int stack_of[100000000];
原因很明显,直接在栈上申请如此大的数组,导致栈空间溢出,触犯了OS对于栈空间大小的限制,所以出Core(这里是否出Core还和OS对栈空间的大小配置有关,一般为8M)。但是这里要明确一点,真正出Core的代码不是分配栈空间的int stack_of[100000000], 而是后面这句int b=1, 为何?出Core的一种原因是因为对内存的非法访问,在上面的代码中分配数组stack_of时并未访问它,但是在其后声明变量并赋值,就相当于进行了越界访问,继而出Core。为了解释得更详细些,让我们使用gdb来看一下出Core的地方,使用命令gdb a core_file可见:
可知程序出现了段错误“Segmentation fault”, 代码是int b=1这句。我们来查看一下当前的栈信息:
其中可见指令指针rip指向地址为0×400473, 我们来看下当前的指令是什么:
这条movl指令要把立即数1送到0xffffffffe8287bfc(%rbp)这个地址去,其中rbp存储的是帧指针,而0xffffffffe8287bfc很明显是一个负数,结果计算为-400000004。这就可以解释了:其中我们申请的int stack_of[100000000]占用400000000字节,b是int类型,占用4个字节,且栈空间是由高地址向低地址延伸,那么b的栈地址就是0xffffffffe8287bfc(%rbp),也就是$rbp-400000004。当我们尝试访问此地址时:
可以看到无法访问此内存地址,这是因为它已经超过了OS允许的范围。
下面我们把程序进行改进:
#include “stdio.h”
int main(){
int* stack_of = malloc(sizeof(int)*100000000);
int b=1;
int* a;
*a=b;
}
使用gcc –O3 –g a.c –o a进行编译,运行后会再次Core掉,使用gdb查看栈信息,请见下图:
可见BUG出在第7行,也就是*a=b这句,这时我们尝试打印b的值,却发现符号表中找不到b的信息。为何?原因在于gcc使用了-O3参数,此参数可以对程序进行优化,一个负面效应是优化过程中会舍弃部分局部变量,导致调试时出现困难。在我们的代码中,b声明时即赋值,随后用于为*a赋值。优化后,此变量不再需要,直接为*a赋值为1即可,如果汇编级代码上讲,此优化可以减少一条MOV语句,节省一个寄存器。
此时我们的调试信息已经出现了一些扭曲,为此我们重新编译源程序,去掉-O3参数(这就解释了为何一些大型软件都会有debug版本存在,因为debug是未经优化的版本,包含了完整的符号表信息,易于调试),并重新运行,得到新的core并查看,如下图:
这次就比较明显了,b中的值没有问题,有问题的是a,其指向的地址是非法区域,也就是a没有分配内存导致的Core。当然,本例中的问题其实非常明显,几乎一眼就能看出来,但不妨碍它成为一个例子,用来解释在看Core过程中,需要注意的一些问题。